
How to Train an AI Agent on Your Company Data: A Non-Technical Guide
You can train an AI agent on your company data without a data science team. The two primary methods — Retrieval-Augmented Generation (RAG) and fine-tuning — let you ground a general-purpose AI model in your specific documents, processes, and institutional knowledge. For most businesses, RAG is the faster, safer starting point. Fine-tuning adds depth when your domain has stable, specialised terminology. The smartest deployments combine both.
At Tenfold, we implement AI agents for enterprise operations teams every week. The question we hear most often is not "can AI do this?" — it is "how do we make it know *our* business?" This guide answers that.
Key Takeaways:
There are two core ways to make an AI agent work with your company data: RAG (connecting it to your documents at query time) and fine-tuning (training it on your data directly).
RAG is faster to deploy, cheaper to maintain, and easier to govern — making it the right first move for most organisations.
Fine-tuning is the right choice when your domain uses stable, specialised language that the base model does not already understand.
The bottleneck is rarely the AI. It is the state of your data — scattered, unstructured, and ungoverned.
Most production-grade AI agents combine both approaches: fine-tuning for consistency, RAG for factual accuracy and auditability.
Quick Answer: To train an AI agent on your company data, you either connect it to a curated knowledge base (RAG) so it retrieves relevant documents at the moment of each query, or you fine-tune a base model on a dataset of your company's documents and Q&A pairs. RAG requires no model retraining and keeps your data updatable. Fine-tuning requires more effort but embeds domain expertise permanently into the model's behaviour.
Why a Generic AI Agent Will Fail Your Business
Out-of-the-box AI models are trained on publicly available internet data. They are fluent, fast, and impressively capable — until someone asks them about your refund policy, your onboarding checklist, or the specific terminology your industry uses.
According to IBM, foundation models have generalised knowledge bases populated with publicly available training data from the time of training. They have no knowledge of your latest product release, the policy that changed last quarter, or the internal document your team published yesterday.
The result is a confident-sounding agent that gets your business wrong. That is not a model failure. It is an architecture failure.
The fix is not a better model. It is connecting the right model to the right data.
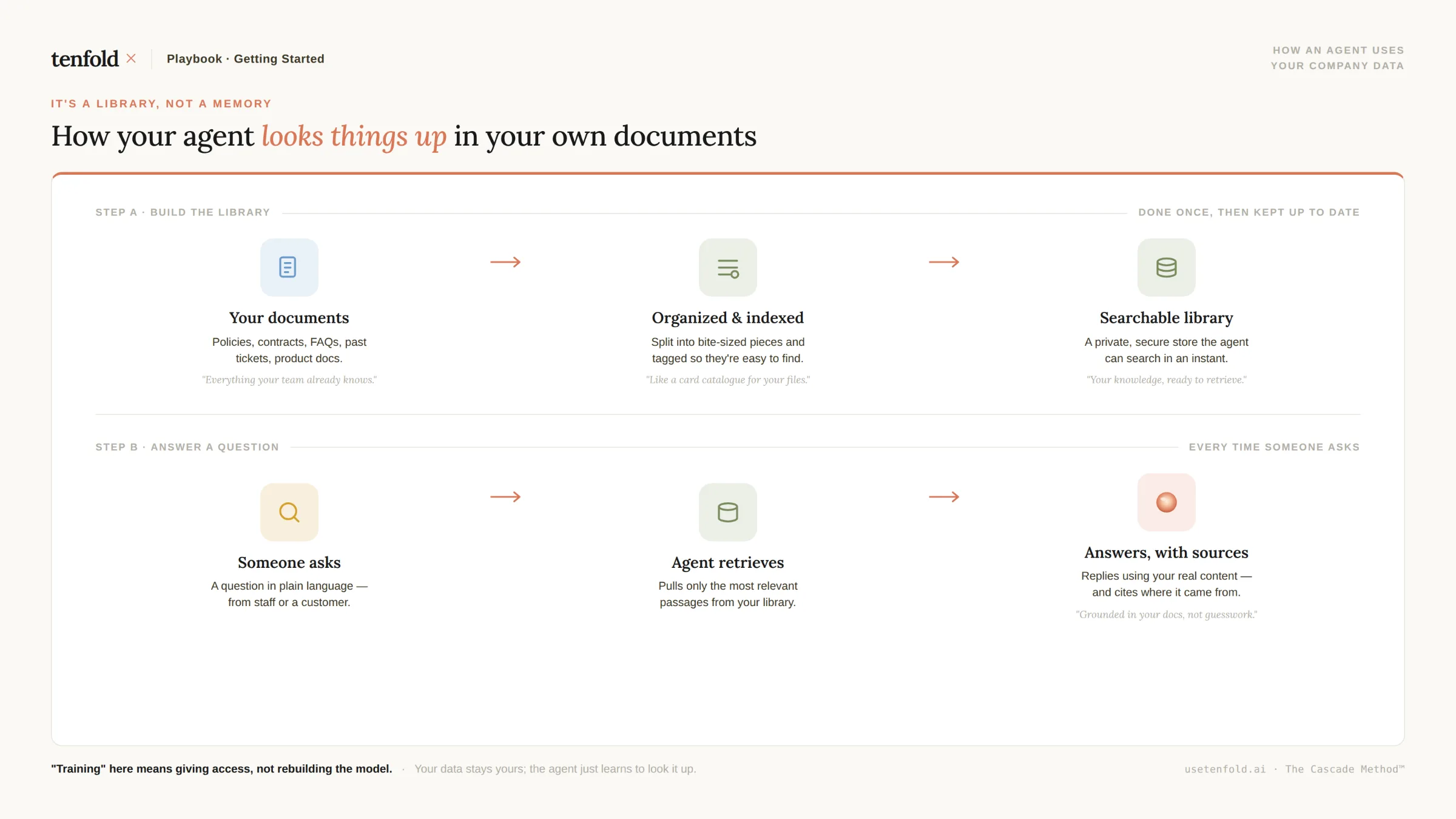
Method 1: RAG — The Fastest Way to Ground an Agent in Your Data
RAG (Retrieval-Augmented Generation) is the most practical starting point for most organisations. Instead of retraining the model, you build a knowledge base from your internal documents and connect the agent to it. When a user asks a question, the system retrieves the most relevant documents and gives them to the model as context before generating a response.
Think of it as giving the agent an open book during every exam — except the book is your internal wiki, your SOPs, your CRM data, and your product documentation.
According to IBM, RAG empowers organisations to avoid high retraining costs when adapting generative AI models to domain-specific use cases, allowing enterprises to complete gaps in a model's knowledge base so it can provide better answers.
Why RAG works well for enterprise teams:
No retraining required. Updating the knowledge base means re-indexing documents, which takes minutes — not weeks.
Full auditability. According to Contextual AI, RAG enables attribution — every response can cite its sources, users can verify information, and auditors can trace decisions.
Data governance. Sensitive documents stay in controlled repositories. Access controls are enforced at query time. Fine-tuning, by contrast, bakes information into model weights — complicating governance and making it difficult to control access to specific information after training.
Lower cost. RAG infrastructure scales efficiently. Adding documents to the knowledge base is inexpensive; fine-tuning requires significant compute and data preparation investment.
What you need to make RAG work:
1. A curated set of internal documents (policies, SOPs, FAQs, product specs, CRM exports)
2. A clean indexing process — documents chunked, labelled, and stored in a searchable format
3. An AI agent framework that connects retrieval to response generation
4. Role-based access controls so the right people retrieve the right documents
The critical point: poorly indexed data equals poor results. Garbage in, garbage out applies here at a very literal level.
Method 2: Fine-Tuning — When You Need Expertise Baked In
Fine-tuning adjusts the internal parameters of a pre-trained model on a narrower, domain-specific dataset. The model does not just look up answers — it *learns* from your data and applies that learning in every response, even without retrieval.
According to Oracle, fine-tuning further trains a foundation model on new data in a smaller, domain-specific dataset, causing the model to adjust some or all of its parameters to improve performance on the specialised domain.
Fine-tuning is the right choice when:
Your domain uses terminology, jargon, or abbreviations the base model does not recognise
You need consistent output formatting — structured reports, classification decisions, compliance documents
Your knowledge base is relatively stable and does not change daily
Latency is critical and you need sub-second responses at high volume
What fine-tuning requires:
A curated dataset of examples — typically question-and-answer pairs or labelled documents
Domain expertise to create and validate those examples
Compute resources (or a managed fine-tuning service)
A retraining process every time your knowledge changes significantly
The significant downside: fine-tuned models are black boxes for specific facts. There is no direct line from a generated answer back to its source. In regulated industries, that auditability gap is a serious concern.
According to MITRIX Technology, fine-tuning shines when domain expertise must be baked into the model itself — particularly when stability, compliance, and consistent outputs are non-negotiable.
The Smart Path: Combining RAG and Fine-Tuning
RAG and fine-tuning are not competitors. The most robust production systems use both.
According to Towards Data Science, the strongest approach combines a model fine-tuned on a company's writing style and internal terminology with RAG for knowledge grounding — fine-tuning gives consistency of voice, RAG gives factual accuracy and auditability.
Here is how the layers work together:
| Layer | What It Does | When to Use It |
|---|---|---|
| Fine-tuning | Embeds domain language, tone, and formatting | Stable knowledge, specialised terminology |
| RAG | Retrieves current, attributable facts at query time | Frequently updated data, compliance needs |
| Agent orchestration | Sequences multi-step tasks across both layers | Complex workflows, cross-system automation |
According to MITRIX Technology, the smartest teams combine fine-tuned models for specialised tasks, RAG for freshness and adaptability, and agents to stitch it all together — a layered strategy that keeps AI both precise and flexible.
At Tenfold, this is exactly the architecture we implement. We do not pick one method and defend it. We design for the specific data environment of each client.
Step-by-Step: How to Get Started Without a Data Science Team
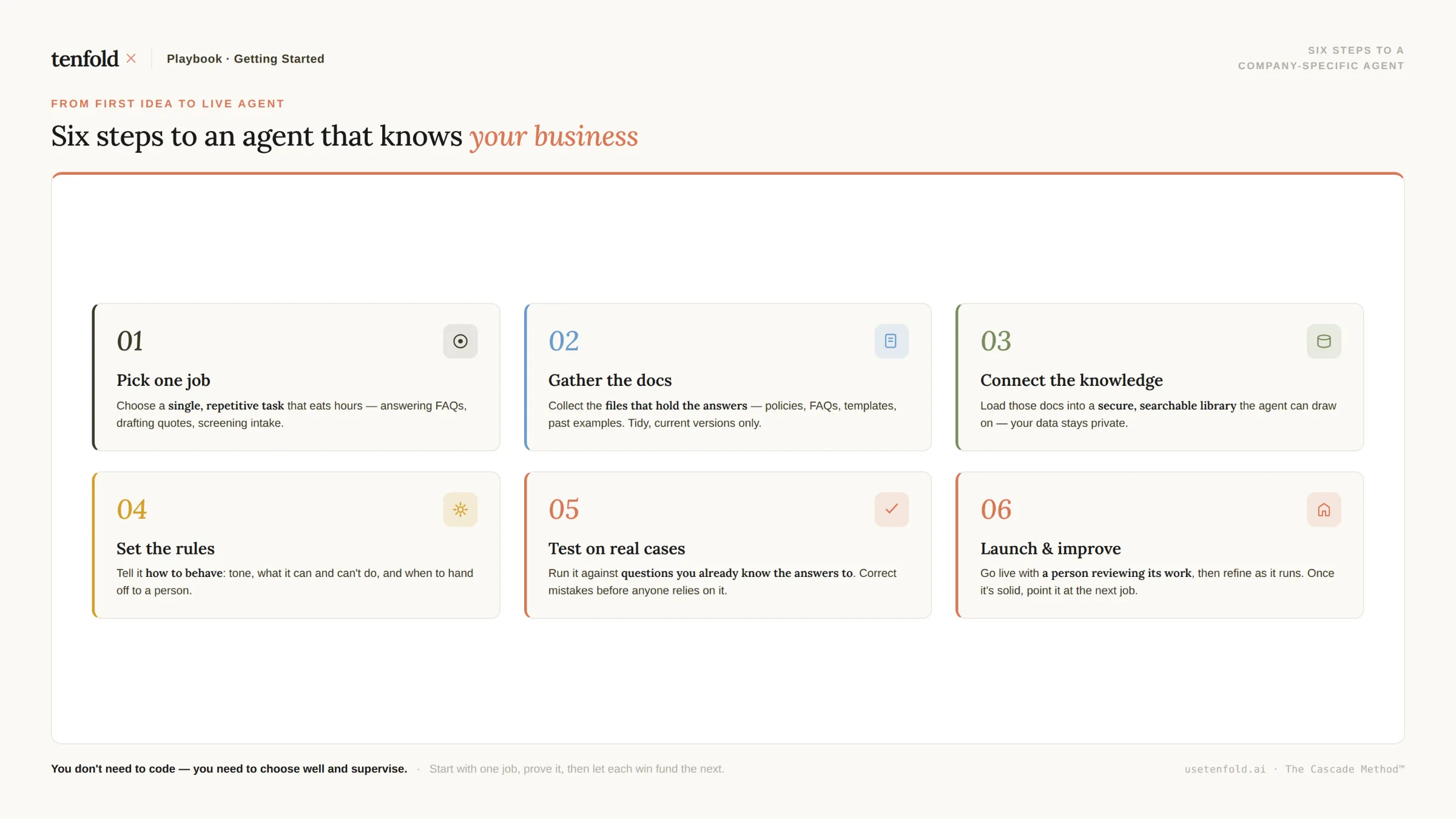
Here is the practical sequence for a non-technical team taking this from idea to working agent.
Step 1: Define the agent's job before you touch the data
Do not start with technology. Start with the task. What specific question should this agent answer, or what specific workflow should it execute? An agent scoped to "answer customer onboarding questions using our internal playbook" is deployable. An agent scoped to "know everything about our business" is not.
Step 2: Audit and clean your data
According to Towards Data Science, the average employee spends two to three hours per week looking for information that already exists somewhere — because institutional knowledge is scattered and unsearchable. That problem does not disappear when you add AI. It gets amplified.
Before indexing anything, remove outdated documents, consolidate duplicates, and establish clear ownership for each knowledge source.
Step 3: Structure your knowledge base
For RAG, your documents need to be chunked into retrievable units, labelled with metadata (department, date, topic), and stored in a searchable index. According to Matillion, RAG requires clean, well-structured documents with good metadata — quality inputs are non-negotiable regardless of the AI approach.
Step 4: Set access controls before deployment
Not every employee should retrieve every document. Role-based access controls at the knowledge base level mean the agent surfaces only what each user is authorised to see. This is governance, not an optional extra.
Step 5: Test on real queries, not demo scenarios
Test with the actual questions your team or customers ask — including the edge cases, the ambiguous phrasing, and the domain-specific abbreviations. If the agent fails on those, the index needs work, not the model.
Step 6: Monitor, iterate, and update the knowledge base
An AI agent is not a one-time deployment. Policies change. Products update. Processes evolve. Build a cadence for refreshing the knowledge base and reviewing agent outputs for accuracy.
The Data Problem Most Organisations Underestimate
Here is the honest assessment: the technology is ready. The models are capable. The frameworks exist.
The bottleneck in almost every AI agent project we encounter at Tenfold is the state of the company's data — not the AI.
Documents stored in multiple systems with no consistent naming convention. Policies that were updated in one place but not another. Knowledge that exists only in the heads of senior employees who have been at the company for fifteen years.
According to Gartner (via Workativ), 33% of software applications will include agentic AI by 2028, up from less than 1% in 2024. That acceleration is happening regardless of whether your internal data is ready for it.
The companies that will extract real value from AI agents are the ones that treat data readiness as a prerequisite, not an afterthought.
Summary
Training an AI agent on your company data is not a technical problem. It is an operational and architectural one. RAG gives you speed, governance, and auditability — making it the right first move for most enterprise teams. Fine-tuning adds consistency and domain expertise when your use case demands it. Combined, they form the foundation of an AI agent that actually knows your business.
At Tenfold, we design and implement these architectures for operations leaders who need results without requiring a dedicated ML team. The proof is in the delivery model — the same agent-first approach we use internally, now available to your organisation.
Frequently Asked Questions
Q: Do I need technical staff to train an AI agent on my company data?
A: Not necessarily. RAG-based implementations can be configured using managed platforms and low-code tools that do not require ML engineering. The more complex work — data cleaning, access controls, and integration with live systems — benefits from specialist support, but the process is far more accessible than most leaders assume.
Q: How long does it take to build an AI agent on company data?
A: A focused RAG implementation with a well-defined scope and clean data can be operational in weeks, not months. The variable that most affects timeline is the state of your internal documentation. Disorganised, outdated, or scattered data adds significant preparation time before any AI work begins.
Q: What is the difference between RAG and fine-tuning in plain terms?
A: RAG gives the agent access to your documents at the moment it answers a question — like an open-book exam. Fine-tuning trains the model on your data directly — like a closed-book exam where the model has studied your material beforehand. RAG is more flexible and easier to update. Fine-tuning is better for consistent, domain-specific outputs.
Q: Can my company data stay private if I use a public AI model?
A: Yes, with the right architecture. RAG keeps your documents in your own controlled repositories — sensitive data is never baked into the model itself. Enterprise platforms from Microsoft, Google, and others include data privacy and governance controls specifically for this purpose.
Q: What types of company data work best for training an AI agent?
A: FAQs, SOPs, product documentation, policy documents, onboarding materials, and CRM data are the highest-value starting points. Unstructured documents — old email threads, meeting notes, informal Slack messages — require significantly more preparation before they can be indexed reliably.
